Table of Contents
What is Deep Classiflie?
- Deep Classiflie is a framework for developing ML models that bolster fact-checking efficiency. Predominantly a research projecte, I plan to extend and maintain this framework in pursuing my own research interests so am sharing it in case it’s of any utility to the broader community.
- As a POC, the initial alpha release of Deep Classiflie generates/analyzes a model that continuously classifies a single individual’s statements (Donald Trump)1 using a single ground truth labeling source (The Washington Post).
-
The Deep Classiflie POC model’s current predictions and performance on the most recent test set can be explored and better understood using the current prediction explorer:
-
the prediction explorer:
-
and the performance explorer:


- This research project initially integrated multiple fact-checkers and should be readily extensible to other statement streams/fact-checkers. The extent to which models built using this framework/approach generalize among different statement issuers is the next primary focus of this research project.
Project Motivation
-
Asymmetries in disinformation diffusion dynamics0 and in rates of generation vs detection suggest building tools that maximize fact-checking efficiency could be of immense societal value. To this end, Deep Classiflie can be used to build and analyze models that leverage previous fact-checking labels to enhance future fact-checking efficiency by identifying new statements most likely to be identified as falsehoods.
- With a few caveats, the performance of the initial POC model built using this framework is remarkably encouraging (see current performance for more detail):
- Global metrics (performance on the entire test set):
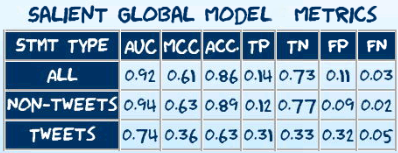
- Local metrics (performance in a local region of confidence):


- Global metrics (performance on the entire test set):
- Future research using this framework is intended to explore the extent to which these claim-classification models generalize across individuals and fact-checking entities. Approaches to sharing and integrating these models into a mutually-enhancing network are also to be investigated.
Model Exploration
The best way to start understanding/exploring the current model is to use the explorers on deepclassiflie.org:
Prediction Explorer
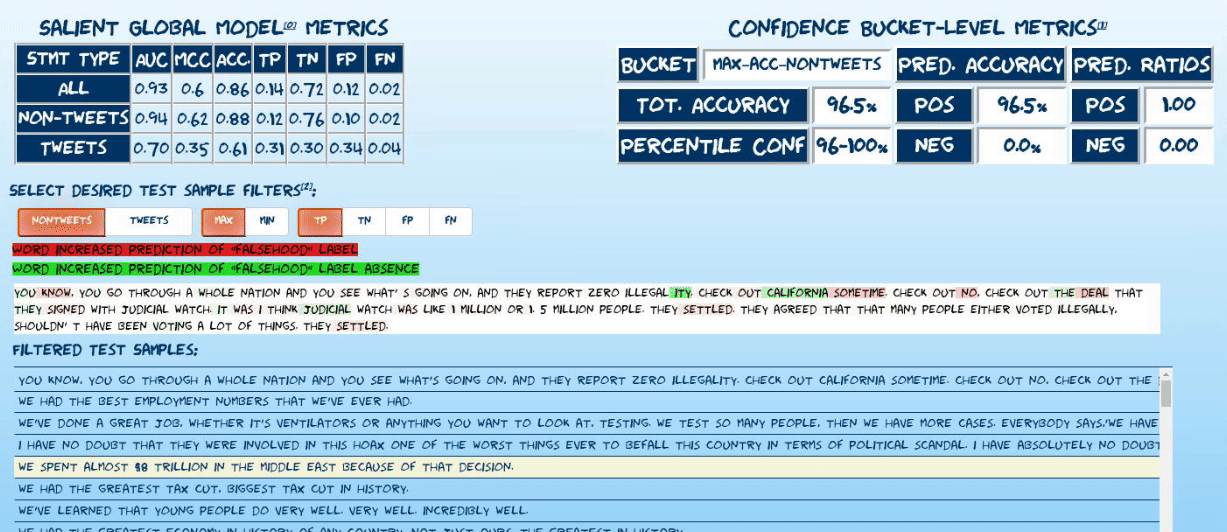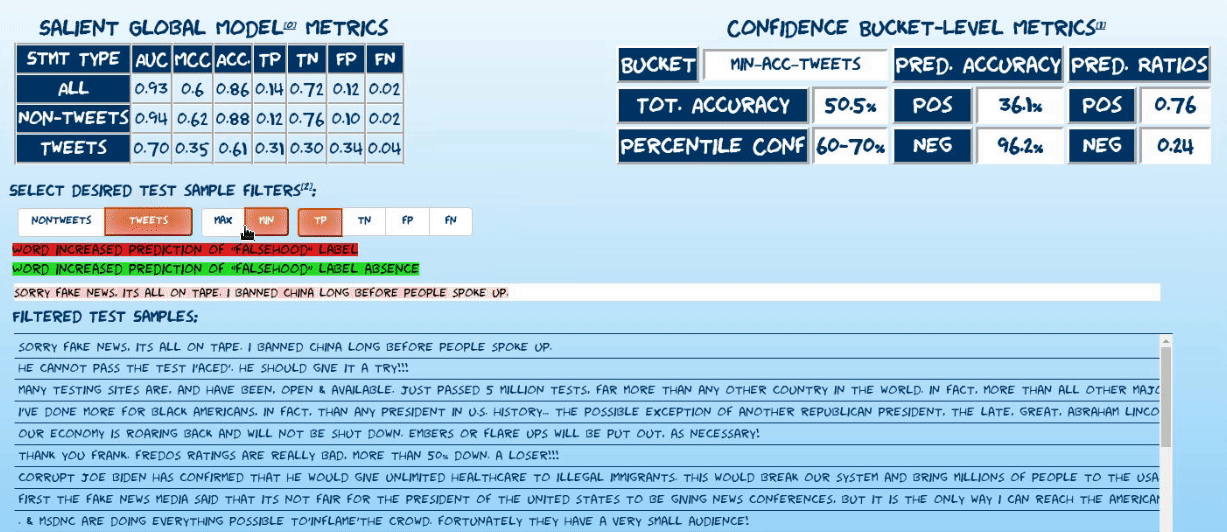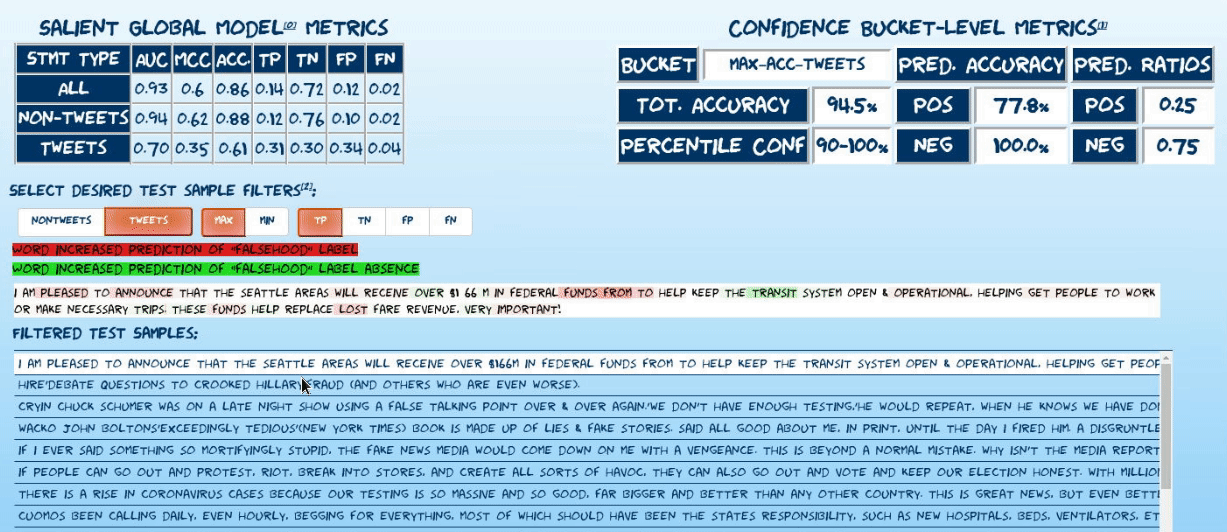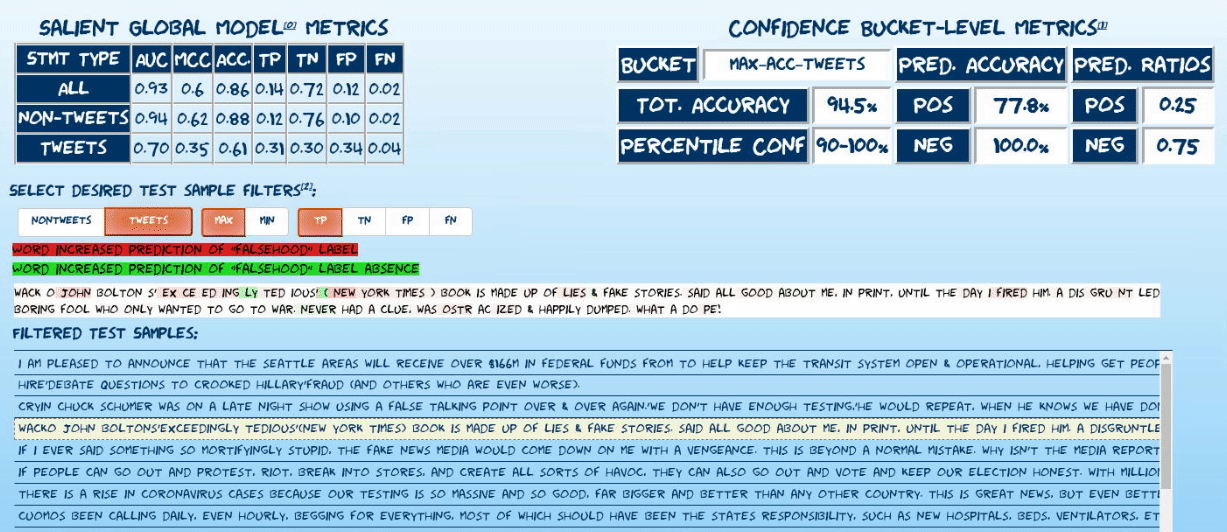
Explore randomly sampled predictions from the test set of the latest model incarnation. The explorer uses captum’s implementation of integrated gradients7 to visualize attributions of statement predictions to tokens in each statement. Read more about explorer below.
Performance Explorer
Explore the performance of the current model incarnation using confusion matrices oriented along temporal and confidence-based axes.
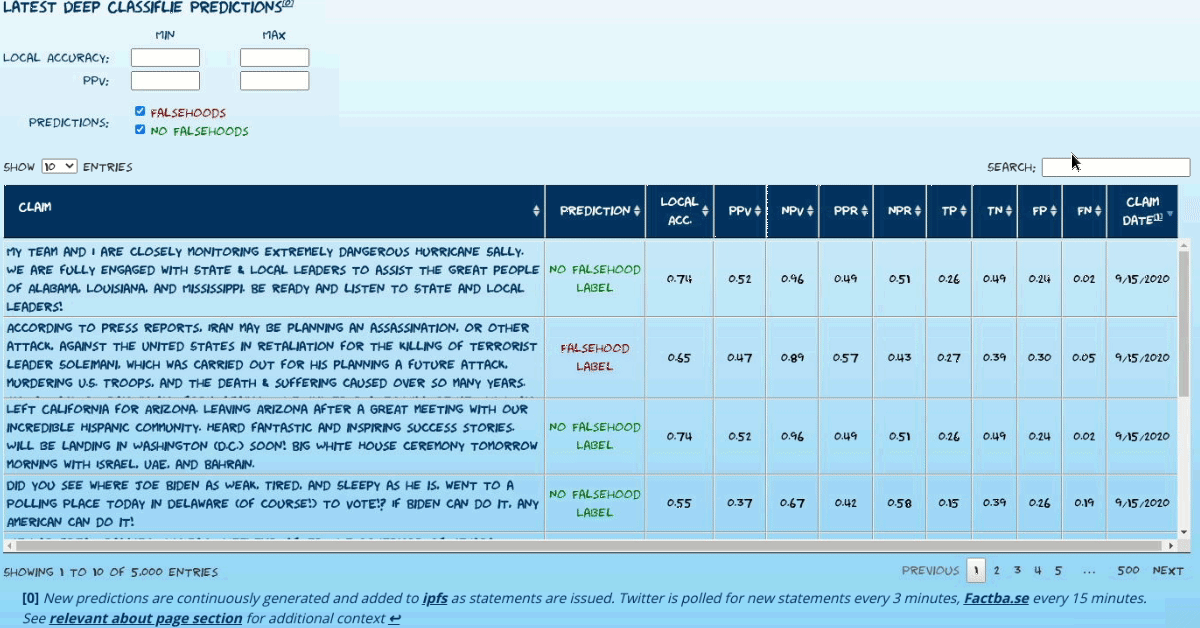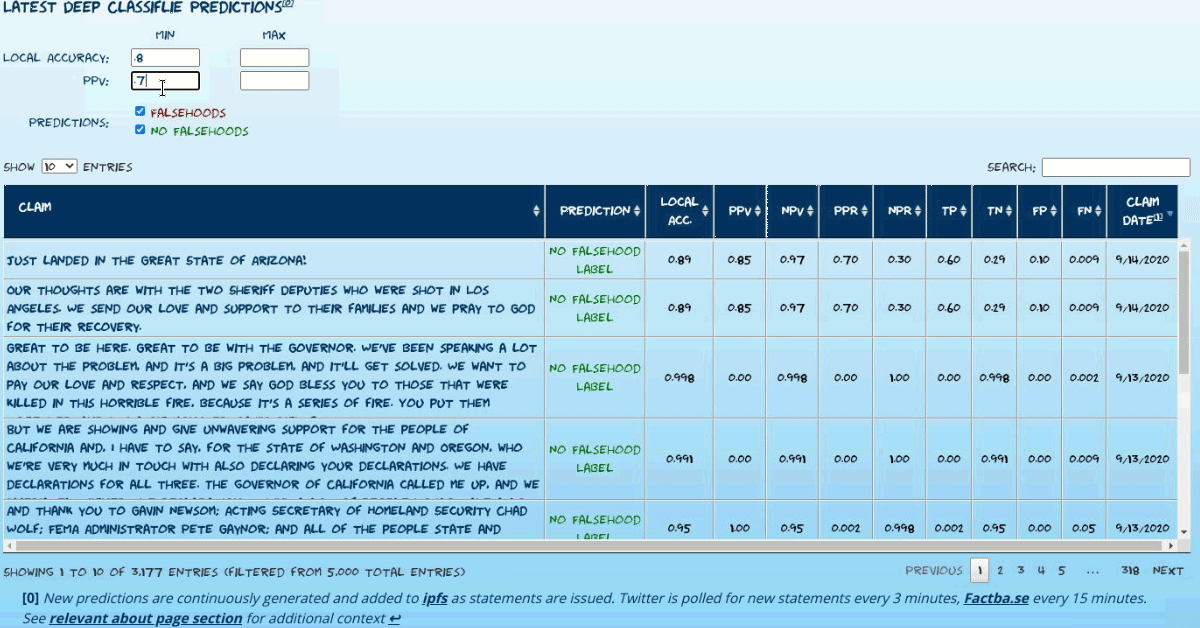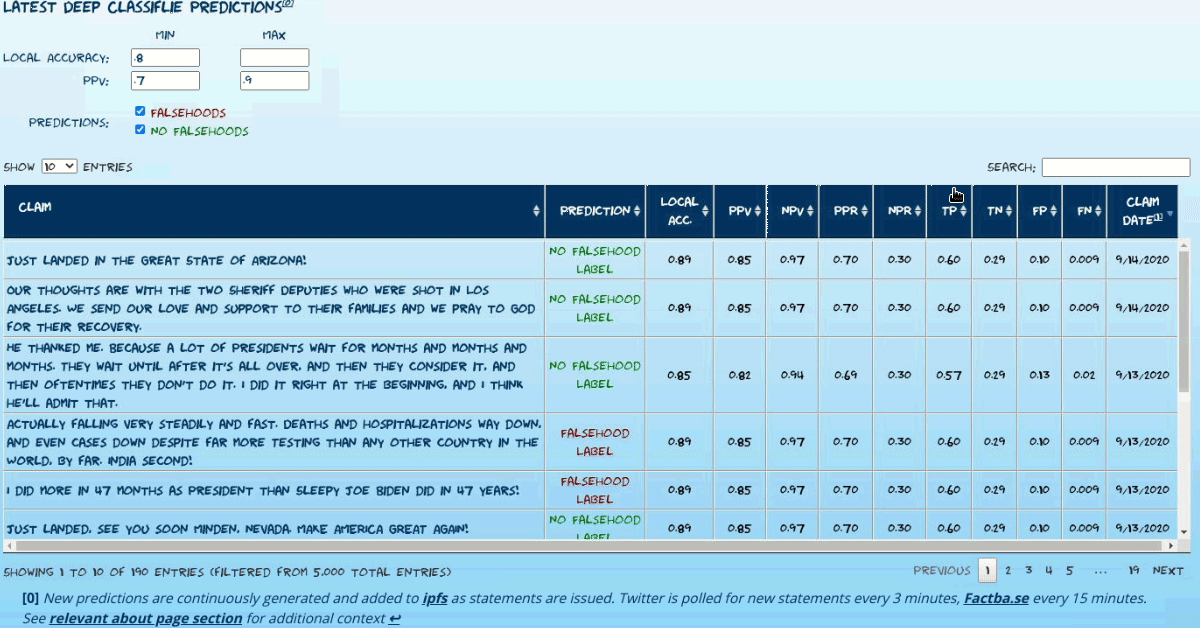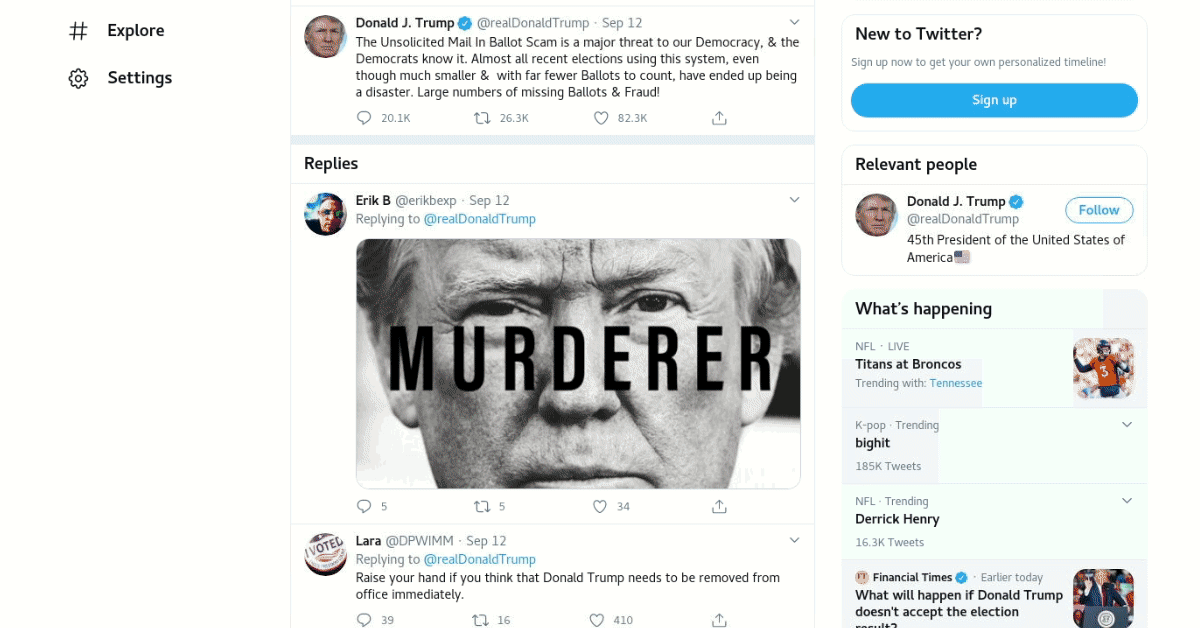
Current Predictions Explorer
Explore current predictions of the latest model. The most recent (max 5000) statements that have yet to be labeled by the currently used fact-checking sources (only Washington Post Factchecker at present) are available.
Live predictions are continuously added via ipfs. Twitter is polled for new statements every 3 minutes, Factba.se every 15 minutes.
This explorer provides fact-checkers a means (one of many possible) of using current model predictions and may also help those building fact-checking systems evaluate the potential utility of integrating similar models into their systems.
Core Components
The entire initial Deep Classiflie system (raw dataset, model, analytics modules, twitter bot etc.) can be built from scratch using the publicly available code here.2
| Component | Description |
|---|---|
| deep_classiflie | Core framework for building, training and analyzing fact-check facilitating ML models. Can operate independently from deep_classiflie_db when training a model using existing dataset collections or when performing inference. Depends on deep_classiflie_db for certain functions such as creating new dataset collections, running the tweetbot, running the analytics modules etc. 3 |
| deep_classiflie_db | Backend datastore for managing Deep Classiflie metadata, analyzing Deep Classiflie intermediate datasets and orchestrating Deep Classiflie model training pipelines. Includes data scraping modules for the initial model data sources (twitter, factba.se, washington post – politifact and the toronto star were removed from an earlier version and may be re-added among others as models for other prominent politicians are explored) |
Dataset Generation
- For simplicity, scrape “ground truth” falsehood labels from a single source (Washington Post Factchecker)
- Scrape a substantial fraction of public statements from multiple sources. (Factba.se, Twitter)
- Use statement hashes and subword representations from a base model (ALBERT8) to remove “false” statements present in the larger “truths” corpus.
- Prepare chronologically disjoint train/dev/test sets (to avoid data leakage) and attempt to reduce undesired superficial class-aligned distributional artifacts that could be leveraged during model training. NNs are lazy, they’ll cheat if we let them.
Model Training
- Fine-tune a base model (currently HuggingFace’s ALBERT implementation with some minor customizations) in tandem with a simple embedding reflecting the semantic shift associated with the medium via which the statement was conveyed (i.e., for the POC, just learn the tweet vs non-tweet transformation) (using Pytorch)
- Explore the latest model’s training session on tensorboard.dev.
- N.B. neuro-symbolic methods6 that leverage knowledge bases and integrate symbolic reasoning with connectionist methods are not used in this model. Use of these approaches may be explored in future research using this framework.
Analysis & Reporting
- Interpret statement-level predictions using captum’s implementation of integrated gradients to visualize attributions of statement predictions to tokens in each statement.
- Test set prediction and model performance exploration dashboards were built using bokeh and Jekyll
- The current prediction explorer was built using datatables and ipfs with pinning provided by pinata
- Two inference daemons poll, analyze and classify new statements:
-
A daemon that publishes via IPFS all new statement classifications and inference output.
-
Automated false statement reports for predictions meeting the desired PPV confidence threshold can be published on twitter via a twitter bot, which leverages Tweepy. The bot h tweets out a statement analysis and model interpretation “report” such as the one below for statements the model deems most likely to be labeled falsehoods (see current performance for more detail):
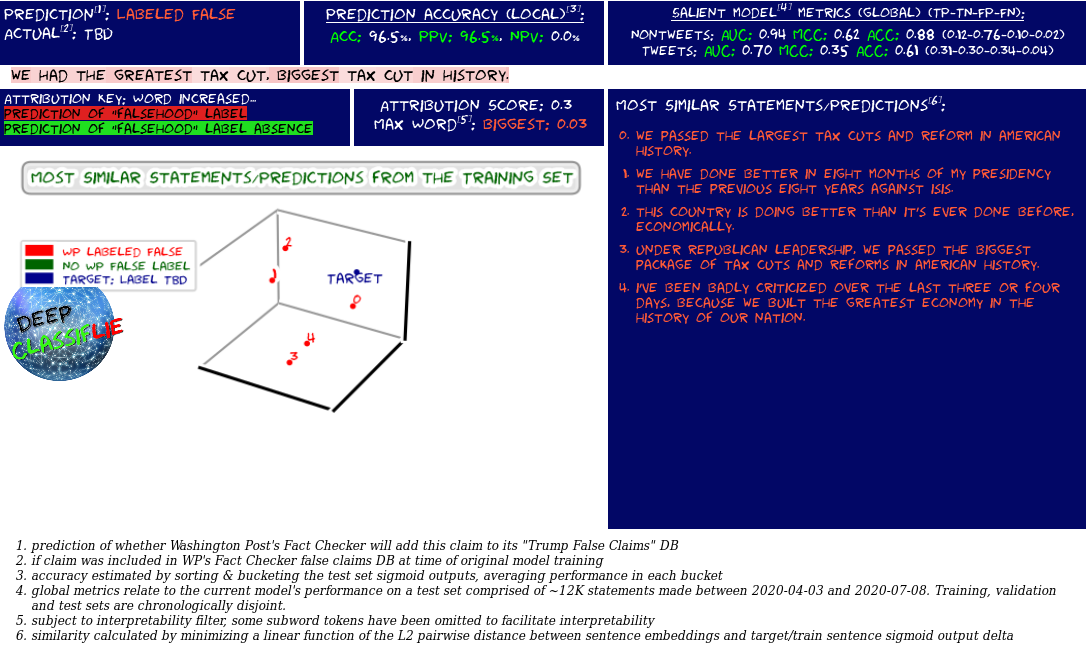
-
- XKCD fans may notice the style of the dashboard explorers and statement reports are XKCD-inspired using the Humor Sans font created by @ch00ftech. Thanks to him (and @xkcd of course!)
Current Performance
Global
Global metrics9 summarized in the table below relate to the current model’s performance on a test set comprised of ~13K statements made between 2020-04-03 and 2020-07-08:
Local
To minimize false positives and maximize the model’s utility, the following approach is used to issue high-confidence predictions:
- All test set predictions are bucketed by model confidence (derived from the raw prediction sigmoid output).
- Various performance metrics are calculated, grouped by confidence bucket (4%/10% of test set for non-tweets/tweets respectively). Most relevantly:
- PPV
- Positive prediction ratio: (bucket true positives + bucket false positives)/#statements in bucket
- Bucket-level accuracy
- Report estimated local accuracy metrics of given prediction by associating it with its corresponding confidence bucket. See caveats regarding recognized performance biasesa
- In the prediction explorer, randomly sample 100 statements (including all confusion matrix classes) from each of four confidence buckets: the maximum and minimum accuracy buckets for each statement type.
- In the prediction explorer, randomly sample 100 statements (including all confusion matrix classes) from each of four confidence buckets: the maximum and minimum accuracy buckets for each statement type.
Noteworthy Features
Dataset generation
- Easily and extensively configurable using yaml configuration files.
- Multiple different class balancing strategies available (oversampling, class ratios etc.)
- “Weakly converge” superficially divergent class distributions using UnivariateDistReplicator abstraction
- Easily experiment with different train/dev/test splits/configurations via declarative DatasetCollection definitions.
Model training
- Automated recursive fine-tuning of the base model with a FineTuningScheduler abstraction
- Configurable label-smoothing4
- Generate and configure thawing schedules for models.
- EarlyStopping easily configurable with multiple non-standard monitor metrics (e.g. mcc)
- Both automatic and manually-specified stochastic weight averaging of model checkpointsf
- Mixed-precision trainingg
Analysis & reporting
- Extensive suite of reporting views for analyzing model performance and global and local levels
- A current prediction explorer that provides fact-checkers a means (one of many possible) of using current model predictions. This dashboard may also help those building fact-checking systems evaluate the potential utility of integrating similar models into their systems.
- Statement and performance exploration dashboards for interpreting model predictions and understanding its performance
- xkcd-themed visualization of UMAP-transformed statement embeddings
Data Pipeline
To conserve resources and for POC research expediency, the current pipeline uses a local relational DB (MariaDB). Ultimately, a distributed data store would be preferable and warranted if this project merits sufficient interest from the community or a POC involving a distributed network of models is initiated.
Deep Classiflie Data Pipeline

False Statement Filter Processes

Distribution Convergence Process

Dataset Generation Process

Configuration
The parameters used in all Deep Classiflie job executions related to the development of the POC model are provided in the configs directory
| Config File | Description |
|---|---|
| config_defaults.yaml | default values and descriptions of all non-sql parameters |
| config_defaults_sql.yaml | default values and descriptions of all sql parameters |
| dataprep_only.yaml | parameters used to generate dataset |
| train_albertbase.yaml | parameters used to recursively train the POC model |
| gen_swa_ckpt.yaml | parameters used to generate an swa checkpoint (current release was built using swa torchcontrib module but will switch to the now-integrated pytorch swa api in the next release) |
| gen_report.yaml | parameters used to generate model analysis report(s) |
| gen_dashboards.yaml | parameters used to generate model analysis dashboards |
| cust_predict.yaml | parameters used to perform model inference on arbitrary input statements |
| tweetbot.yaml | parameters used to run the tweetbot behind @DeepClassiflie |
| infsvc.yaml | parameters used to run the inference service behind the current prediction explorer |
Further Research
- The NLP research community is actively studying precisely what these models learn5. A closer examination of the distributed statement representations learned by Deep Classiflie models is planned. As of writing (2020.08.19) Google has just open-sourced an NLP model interpretability tool named LIT that one could use to further elucidate the patterns identified by Deep Classiflie models. Customizing and extending LIT for exploration of Deep Classiflie model statement representations may be warranted.
- The extent to which these claim-classification models generalize across individuals and fact-checking entities should be explored.
- Approaches to sharing and integrating these models into a mutually-enhancing network are also to be investigated.
- A distributed network of fact-checking model instances each built and fine-tuned for a given salient public figure using a framework such as Deep Classiflie might allow human fact-checkers to allocate their attention more efficiently to verifying high-probability falsehoods.
- One can envisage a positive feedback loop developing wherein improved fact-checking coverage and latency yield increases in model-training data with the resultant improved model accuracy in turn driving further fact-checking efficiencies. The prospect of this potential value I think merits investment in research frameworks such as Deep Classiflie that attempt to explore and extend the efficacy of ML-driven enhancements to fact-checking systems.
Model Replication
Instructions
N.B. before you begin, the core external dependency is admin access to a mariadb or mysql DB
- Clone deep_classiflie and deep_classiflie_db (make them peer directories if you want to minimize configuration)
git clone https://github.com/speediedan/deep_classiflie.git git clone https://github.com/speediedan/deep_classiflie_db.git - install conda if necessary. Then create and activate deep_classiflie virtual env:
conda env create -f ./deep_classiflie/assets/deep_classiflie.yml conda activate deep_classiflie - clone captum and HuggingFace’s transformers repos. Install transformers binaries.:
git clone https://github.com/pytorch/captum.git git clone https://github.com/huggingface/transformers cd transformers pip install . -
Install mariadb or mysql DB if necessary.
-
These are the relevant DB configuration settings used for the current release of Deep Classiflie’s backend. Divergence from this configuration has not been tested and may result in unexpected behavior.
collation-server = utf8mb4_unicode_ci init-connect='SET NAMES utf8mb4' character-set-server = utf8mb4 sql_mode = 'STRICT_TRANS_TABLES,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,ANSI_QUOTES' transaction-isolation = READ-COMMITTED - copy/update relevant Deep Classiflie config file to $HOME dir
cp ./deep_classiflie_db/db_setup/.dc_config.example ~ mv .dc_config.example .dc_config vi .dc_config# configure values appropriate to your environment and move to $HOME # Sorry I haven't had a chance to write a setup config script for this yet... export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64" export CUDA_HOME=/usr/local/cuda export PYTHONPATH="${PYTHONPATH}:${HOME}/repos/edification/deep_classiflie:${HOME}/repos/captum:${HOME}/repos/transformers:${HOME}/repos/edification/deep_classiflie_db" export DC_BASE="$HOME/repos/edification/deep_classiflie" export DCDB_BASE="$HOME/repos/edification/deep_classiflie_db" export PYTHONUNBUFFERED=1 export DCDB_PASS="dcbotpasshere" export DCDB_USER="dcbot" export DCDB_HOST="hostgoeshere" export DCDB_NAME="deep_classiflie" - execute Deep Classiflie DB backend initialization script:
cd deep_classiflie_db/db_setup ./deep_classiflie_db_setup.sh deep_classiflieEnsure you have access to a DB user with administrator privs. “admin” in the case above.
- login to the backend db and seed historical tweets (necessary as only most recent 3200 can currently be retrieved directly from twitter)
mysql -u dcbot -p use deep_classiflie source dcbot_tweets_init_20200910.sql exit - copy over relevant base model weights to specified model_cache_dir:
# model_cache_dir default found in configs/config_defaults.yaml # it defaults to $HOME/datasets/model_cache/deep_classiflie/ cd {PATH_TO_DEEP_CLASSIFLIE_BASE}/deep_classiflie/assets/ cp albert-base-v2-pytorch_model.bin albert-base-v2-spiece.model {MODEL_CACHE_DIR}/ - Run deep_classiflie.py with the provided config necessary to download the raw data from the relevant data sources (factba.se, twitter, washington post), execute the data processing pipeline and generate the dataset collection.
cd deep_classiflie ./deep_classiflie.py --config "{PATH_TO_DEEP_CLASSIFLIE_BASE}/configs/dataprep_only.yaml" See relevant process diagrams to better understand the dataset generation pipeline and process.- While I have set seeds for the majority of randomized processes in the data pipeline, there are a couple points in the pipeline that remain non-deterministic at the moment (see issue #). As such, the dataset generation log messages should approximate those below, but variation within 1% is expected.
(...lots of initial data download/parsing message above...) 2020-08-14 16:55:22,165:deep_classiflie:INFO: Proceeding with uninitialized base model to generate dist-based duplicate filter 2020-08-14 16:55:22,501:deep_classiflie:INFO: Predictions from model weights: 2020-08-14 16:57:14,215:deep_classiflie:INFO: Generated 385220 candidates for false truth analysis 2020-08-14 16:57:15,143:deep_classiflie:INFO: Deleted 7073 'truths' from truths table based on similarity with falsehoods enumerated in base_false_truth_del_cands 2020-08-14 16:57:30,181:deep_classiflie:INFO: saved 50873 rows of a transformed truth distribution to db 2020-08-14 16:57:30,192:deep_classiflie:DEBUG: DB connection obtained: <mysql.connector.pooling.PooledMySQLConnection object at 0x7f8216056e50> 2020-08-14 16:57:30,220:deep_classiflie:DEBUG: DB connection closed: <mysql.connector.pooling.PooledMySQLConnection object at 0x7f8216056e50> 2020-08-14 16:57:30,221:deep_classiflie:INFO: Building a balanced dataset from the following raw class data: 2020-08-14 16:57:30,221:deep_classiflie:INFO: Label True: 50873 records 2020-08-14 16:57:30,221:deep_classiflie:INFO: Label False: 19261 records 2020-08-14 16:57:49,281:deep_classiflie:INFO: Saving features into cached file /home/speediedan/datasets/temp/deep_classiflie/train_converged_filtered.pkl 2020-08-14 16:58:06,552:deep_classiflie:INFO: Saving features into cached file /home/speediedan/datasets/temp/deep_classiflie/val_converged_filtered.pkl 2020-08-14 16:58:11,714:deep_classiflie:INFO: Saving features into cached file /home/speediedan/datasets/temp/deep_classiflie/test_converged_filtered.pkl 2020-08-14 16:58:14,331:deep_classiflie:DEBUG: Metadata update complete, 1 record(s) affected. ... - Recursively train the deep classiflie POC model:
cd deep_classiflie ./deep_classiflie.py --config "{PATH_TO_DEEP_CLASSIFLIE_BASE}/configs/train_albertbase.yaml" - Generate an swa checkpoint (current release was built using swa torchcontrib module but will switch to the now-integrated pytorch swa api in the next release):
cd deep_classiflie ./deep_classiflie.py --config "{PATH_TO_DEEP_CLASSIFLIE_BASE}/configs/gen_swa_ckpt.yaml" - Generate model analysis report(s) using the generated swa checkpoint:
# NOTE, swa checkpoint generated in previous step must be added to gen_report.yaml cd deep_classiflie ./deep_classiflie.py --config "{PATH_TO_DEEP_CLASSIFLIE_BASE}/configs/gen_report.yaml" - Generate model analysis dashboards:
# NOTE, swa checkpoint generated in previous step must be added to gen_dashboards.yaml cd deep_classiflie ./deep_classiflie.py --config "{PATH_TO_DEEP_CLASSIFLIE_BASE}/configs/gen_dashboards.yaml" -
configure jekyll static site generator to use bokeh dashboards locally:
#prereqs sudo apt-get install ruby-full build-essential zlib1g-dev #add ruby gems to user profile echo '# Install Ruby Gems to ~/gems' >> ~/.bashrc echo 'export GEM_HOME="$HOME/gems"' >> ~/.bashrc echo 'export PATH="$HOME/gems/bin:$PATH"' >> ~/.bashrc source ~/.bashrc #install jekyll (ensure you're in the build dir (docs)) gem install jekyll bundler #to get nokogiri to install, you may need to be root sudo gem install nokogiri #vi ./deep_classiflie/docs/Gemfile source 'https://rubygems.org' gem 'nokogiri' gem 'rack', '~> 2.1.4' gem 'rspec' gem 'jekyll-theme-cayman' gem "github-pages", "~> 207", group: :jekyll_plugins gem "activesupport", ">= 6.0.3.1" gem 'jekyll-sitemap' gem "kramdown", ">=2.3.0" #note if just updating components, best approach is to update all bundle update #start local server from ./deep_classiflie/docs/ cd ./deep_classiflie/docs/ bundle exec jekyll serve
Model Replication and Exploration with Docker
Instructions
As of writing (2020.10.11), Docker Compose does not fully support GPU provisioning so using the docker cli w/ –gpus flag here.
- Pull image from docker hub
sudo docker pull speediedan/deep_classiflie:v0.1.3 - Recursively train model using latest dataset.
- create a local directory to bind mount and use for exploring experiment output and start training container
mkdir /tmp/docker_experiment_output sudo docker container run --rm -d --gpus all --mount type=bind,source=/tmp/docker_experiment_output,target=/experiments --name deep_classiflie_train deep_classiflie:v0.1.3 \ conda run -n deep_classiflie python deep_classiflie.py --config /home/deep_classiflie/repos/deep_classiflie/configs/docker_train_albertbase.yaml - run tensorboard container to follow training progress (~6 hrs on a single GPU)
sudo docker container run --rm -d --gpus all --mount type=bind,source=/tmp/docker_experiment_output,target=/experiments -p 6006:6006 --workdir /experiments/deep_classiflie/logs --name deep_classiflie_tb deep_classiflie:v0.1.3 conda run -n deep_classiflie tensorboard --host 0.0.0.0 --logdir=/experiments/deep_classiflie/logs --reload_multifile=true
- create a local directory to bind mount and use for exploring experiment output and start training container
- Use a trained checkpoint to evaluate test performance
- start the container with a local bind mount
sudo docker container run --rm -it --gpus all --mount type=bind,source=/tmp/docker_experiment_output,target=/experiments --name deep_classiflie_explore deep_classiflie:v0.1.3 - update the docker_test_only.yaml file, passing the desired inference path (e.g. /experiments/deep_classiflie/checkpoints/20201010172113/checkpoint-0.5595-29-148590.pt)
vi configs/docker_test_only.yaml ... inference_ckpt: "/experiments/deep_classiflie/checkpoints/20201010172113/checkpoint-0.5595-29-148590.pt" ... - evaluate on test set
conda run -n deep_classiflie python deep_classiflie.py --config /home/deep_classiflie/repos/deep_classiflie/configs/docker_test_only.yaml
- start the container with a local bind mount
- Run custom predictions
- update model checkpoint used for predictions with the one you trained
vi /home/deep_classiflie/repos/deep_classiflie/configs/docker_cust_predict.yaml ... inference_ckpt: "/experiments/deep_classiflie/checkpoints/20201010172113/checkpoint-0.5595-29-148590.pt" ... - add tweets or statements to do inference/interpretation on as desired by modifying /home/deep_classiflie/datasets/explore_pred_interpretations.json
- generate predictions
conda run -n deep_classiflie python deep_classiflie.py --config /home/deep_classiflie/repos/deep_classiflie/configs/docker_cust_predict.yaml --pred_inputs /home/deep_classiflie/datasets/explore_pred_interpretations.json - review prediction interpretation card in local host browser,
chrome /tmp/docker_experiment_output/deep_classiflie/logs/20201011203013/inference_output/example_stmt_1_0.png
- update model checkpoint used for predictions with the one you trained
Caveats
- [a] The distance threshold for filtering out "false truths" using base model embeddings matches falsehoods to their corresponding truths with high but imperfect accuracy. This fuzzy matching process will result in a modest upward performance bias in the test results. Model performance on datasets built using the noisy matching process (vs exclusively hash-based) improved by only ~2% globally with gains slightly disproportionately going to more confident buckets. This places a relatively low ceiling on the magnitude of the performance bias introduced through this filtering. The precise magnitude of this bias will be quantified in the future via one or both of the following methods ↩:
- once the project's author (or another contributor) have sufficient bandwidth to execute a comprehensive manual statement de-duplication, the results of that manual de-duplication can be compared to the noisy approach to quantify the bias.
- when the next set of ground truth label data are released by the Washington Post, an estimated vs actual performance comparison can be performed
- [b] The module used to bootstrap the POC model's tweet history by crawling factba.se needs to be refactored and added into the initial dataset bootstrap process. This is presently one of many issues in the backlog. ↩
- [c] Deep Classiflie depends upon deep_classiflie_db (initially released as a separate repository) for much of its analytical and dataset generation functionality. Depending on how Deep Classiflie evolves (e.g. as it supports distributed data stores etc.), it may make more sense to integrate deep_classiflie_db back into deep_classiflie. ↩
- [d] It's notable that the model suffers a much higher FP ratio on tweets relative to non-tweets. Exploring tweet FPs, there are a number of plausible explanations for this discrepancy which could be explored in future research. ↩
- [e] Still in early development, there are significant outstanding issues (e.g. no tests yet!) and code quality shortcomings galore, but any constructive thoughts or contributions are welcome. I'm interested in using ML to curtail disinformation, not promulgate it, so I want to be clear -- this is essentially a fancy sentence similarity system with a lot of work put into building the dataset generation and model analysis data pipelines (I have a data engineering background, not a software engineering one).↩
- [f] Previous versions used the swa module from torchcontrib before it graduated to core pytorch.↩
- [g] Previous versions used NVIDIA's native apex before AMP was integrated into pytorch↩
- [h] N.B. This daemon may violate Twitter's policy w.r.t. tweeting sensitive content if the subject's statements contain such content (no content-based filtering is included in the daemon). @DeepClassflie initially tested the Deep Classiflie twitter daemon but will post only framework-related announcements moving forward.↩
Citing Deep Classiflie
Please cite:
@misc{Dan_Dale_2020_4046591,
author = {Dan Dale},
title = {{Deep Classiflie: Shallow fact-checking with deep neural networks}},
month = sep,
year = 2020,
doi = {10.5281/zenodo.4046591},
version = {v0.1.3-alpha},
publisher = {Zenodo},
url = {https://zenodo.org/record/4046591}
}
Feel free to star the repo as well if you find it useful or interesting. Thanks!
References and Notes
- [0] S. Vosoughi, D. Roy, S. Aral, The spread of true and false news online. Science 359, 1146–1151 (2018). ↩
- [1] Please understand, the initial politician modeled was chosen principally to maximize the volume of freely available labeled data. Maximizing the probability of this POC's success meant leveraging the largest corpus of classified statements. The downside of this decision in our polarized environment unfortunately might be to allow partisan sentiment to obfuscate the core focus of this project: building tools to help curtail disinformation in our information landscape, irrespective of its source. ↩
- [2] Note that Twitter only makes freely accessible the most recent 3200 tweets in a user's timeline. To obtain older data for the first modeled politician, one can bootstrap using the archival tweet data table provided. ↩
- [3] Though the entire system can be built from scratch, to make a subset of system functionality (primarily model training and inference) more easily accessible, a Docker container release is planned. ↩
- [4] Rafael Muller, Simon Kornblith, and Geoffrey Hinton. When Does Label Smoothing Help? NeurIPS (2019). ↩
- [5] Anna Rogers, Olga Kovaleva, and Anna Rumshisky. 2020. A primer in BERTology: What we know about how BERT works. arXiv preprint arXiv:2002.12327. ↩
- [6] Alessandro Oltramari, Jonathan Francis, Cory Henson, Kaixin Ma, and Ruwan Wickramarachchi. 2020. Neuro-symbolic Architectures for Context Understanding. arXiv preprint arXiv:2003.04707 (2020). ↩
- [7] Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Axiomatic attribution for deep networks. arXiv preprint arXiv:1703.01365 (2017). ↩
- [8] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942, (2019). ↩
- [9] Metric definitions: AUC, MCC, ACC. = simple accuracy ↩
License
